Training Without a Supercluster: Decoupled DiLoCo and What It Means for Frontier AI
A systems read on goodput, hardware fungibility, and why training is about to federate while inference keeps concentrating. Companion to the IBM Mixture of Experts episode on Decoupled DiLoCo, DeepSeek V4, and IBM Granite 4.1 + Bob.
Google DeepMind's launch blog post on Decoupled DiLoCo [1] buries the most interesting result. Most coverage led with the bandwidth number, which is 0.84 Gbps where conventional data-parallel needed 198 Gbps. That number is real and it is impressive, but the result that should change how anyone thinks about frontier training is a different one: the goodput gap.
Goodput is the metric worth paying attention to
Goodput is the fraction of training time that is actually doing useful work. In distributed training, chips can be powered on, drawing electricity, and executing instructions while still doing nothing useful, because they are stalled waiting for a peer that crashed three steps ago to recover. Throughput counts what the chips run, while goodput only counts what they run that contributes to the final model.
At frontier scale, this gap is enormous. The DeepMind team ran chaos-engineering simulations with 1.2 million chips under realistic failure rates, and the resulting goodput comparison is shown below.
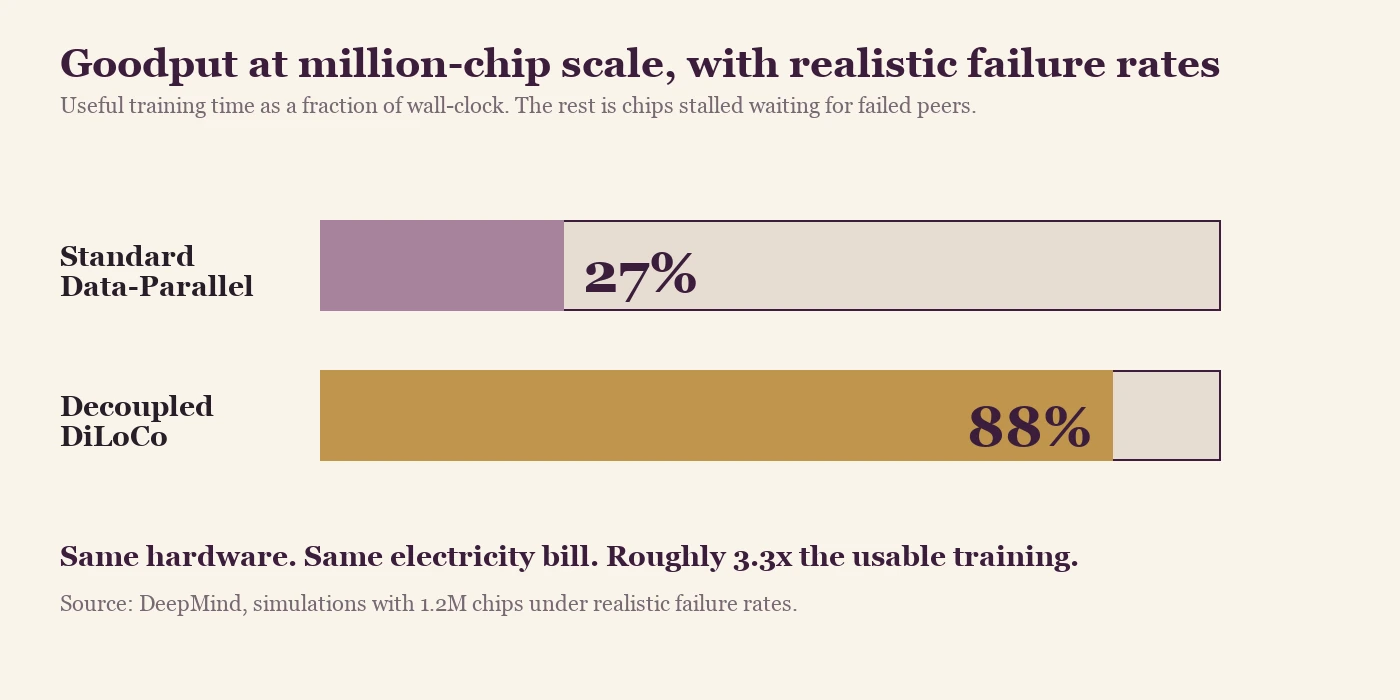 Useful training time as a fraction of wall-clock. Conventional data-parallel collapses to 27% goodput at this scale because every failure stalls every chip until the failed unit comes back. Decoupled DiLoCo's asynchronous learner units keep training when peers fail.
Useful training time as a fraction of wall-clock. Conventional data-parallel collapses to 27% goodput at this scale because every failure stalls every chip until the failed unit comes back. Decoupled DiLoCo's asynchronous learner units keep training when peers fail.
The 27% number is worth reading twice. At million-chip scale, conventional data-parallel training throws away roughly three-quarters of the compute it is burning, so paying for a million chips delivers the useful work of only about 270,000 chips. DiLoCo flips that ratio, and paying for a million chips delivers the useful work of about 880,000 chips. The same hardware running on the same electricity bill produces roughly 3.3 times as much usable training under DiLoCo as it does under conventional data-parallel.
Distributed systems went through this same shift twenty years ago, when the field stopped quoting peak throughput at idle and started quoting tail latency under realistic load. Frontier training is in the same place now. Peak FLOPs and MFU (Model FLOPs Utilization) were the dominant metrics for a decade, while goodput under realistic failure rates is the metric that matters in production going forward.
How the original DiLoCo actually works
Standard distributed training (Data Parallel, Fully Sharded Data Parallel (FSDP), and Zero Redundancy Optimizer (ZeRO)-style) synchronizes gradients across all workers on every single step, which means every chip waits for every other chip. Above a certain scale, the synchronization cost dominates everything else in the run.
The original DiLoCo [2] threw out that assumption by splitting training into an inner loop and an outer loop. Each learner runs ~500 inner AdamW steps locally on its own data shard with no cross-learner communication. At the end of the round, each learner computes a single pseudo-gradient, which captures the net change in its parameters over those 500 steps. That single tensor is what travels across the wide-area network (WAN). A central synchronizer averages the pseudo-gradients, applies an outer optimizer (Nesterov momentum rather than AdamW), and ships new base parameters back to every learner. The next round then begins on the updated base.
 Each learner runs ~500 AdamW steps on local data with no cross-DC traffic, then ships one pseudo-gradient (the round's net parameter change) to the synchronizer. The outer optimizer merges the pseudo-gradients and ships new base parameters back. The overall result is one round-trip per ~500 inner steps, which requires roughly 500x less inter-worker bandwidth than vanilla data-parallel.
Each learner runs ~500 AdamW steps on local data with no cross-DC traffic, then ships one pseudo-gradient (the round's net parameter change) to the synchronizer. The outer optimizer merges the pseudo-gradients and ships new base parameters back. The overall result is one round-trip per ~500 inner steps, which requires roughly 500x less inter-worker bandwidth than vanilla data-parallel.
Why does this converge to the same loss as fully synchronous training? Each pseudo-gradient is a multi-step accumulated update, equivalent to a very large effective batch that has already been smoothed across hundreds of local steps. Gradient noise that would normally average out across workers within a single step instead averages out across time within a single worker. The math holds up in practice: DiLoCo on 8 workers hit the same loss as fully synchronous training while communicating ~500x less.
Why Nesterov momentum on the outside? AdamW seems like the obvious choice because it is what the inner loop uses. The outer loop is operating on already-accumulated multi-step updates, however, where Nesterov's look-ahead behavior beats AdamW's per-parameter adaptive scaling. In testing, Nesterov on the outside paired with AdamW on the inside beat every other combination the DeepMind team tried.
DiLoCo is a new dimension of parallelism. Data Parallel, Tensor Parallel, Pipeline Parallel, and FSDP all assume tight intra-cluster synchronization. DiLoCo adds an inter-cluster dimension that lives on top, with sync frequency thousands of times lower than any of the existing dimensions.
What "decoupled" actually means
Original DiLoCo still requires the synchronizer round to be globally coordinated, which means every learner has to ship its pseudo-gradient at roughly the same time and the outer optimizer waits until all updates arrive before producing the new base. As a consequence, one slow or failed learner stalls the entire round.
Decoupled DiLoCo [3] removes that requirement through three specific mechanisms.
Minimum quorum. The synchronizer does not wait for every learner. Once a configurable threshold of learners (for example, 6 out of 8) have shipped their pseudo-gradients, it commits an outer update, and stragglers fold in when they arrive, weighted appropriately.
Adaptive grace window. Even after the quorum is met, the synchronizer waits a short adjustable period for late arrivals. If historical rounds show most learners arriving inside the window, it shrinks; if many arrive just after the cutoff, it grows.
Dynamic token-weighted merging. A learner that processed 2× the tokens this round counts ~2× more in the merge. This is what makes mixing TPU v6e and v5p generations work without losing model quality: the faster generation contributes more updates per wall-clock hour, and the merge math accounts for it directly.
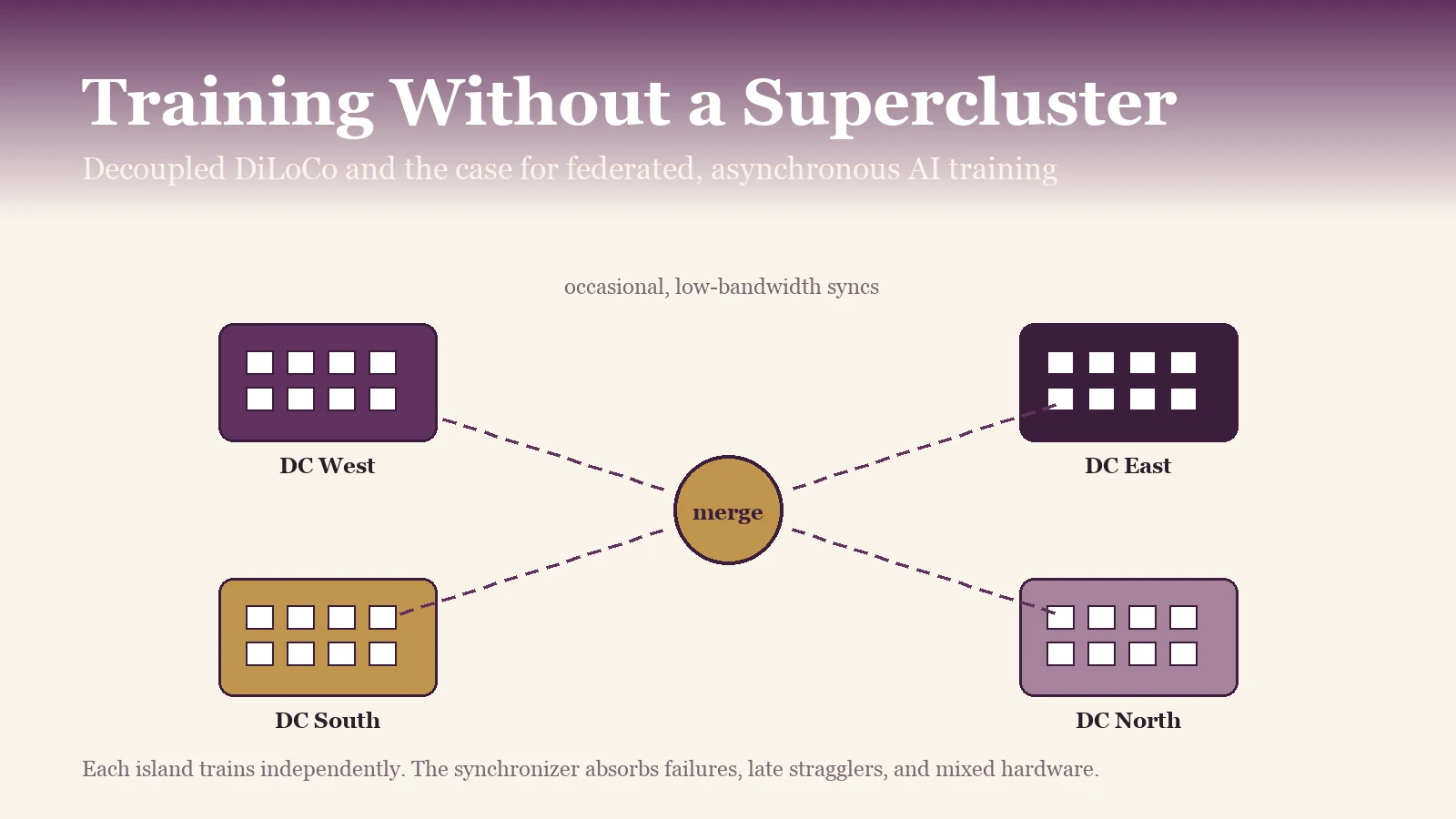
Islands of compute train independently and synchronize occasionally through a central merger. No island has to wait for any other to make progress.
Taken together, these three mechanisms mean that no learner stalls because of any other learner. A chip failure, a network blip, a slow region, or a decommissioning event no longer halts training, and the failed unit rejoins when it recovers and resumes contributing updates.
The bandwidth savings come directly from this design.
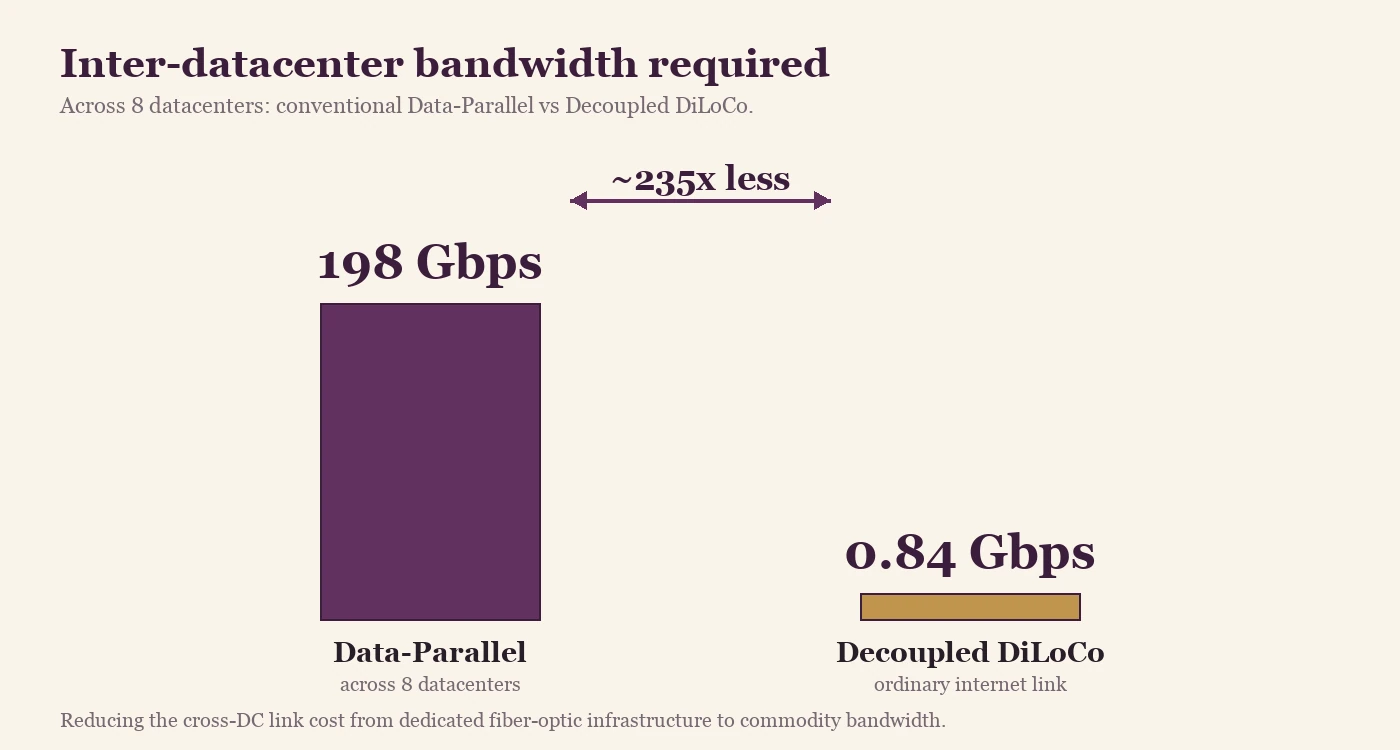 Conventional data-parallel across 8 datacenters needs roughly 198 Gbps of bandwidth between sites — the kind of dedicated fiber-optic link normally reserved for the largest cloud regions. Decoupled DiLoCo reaches the same training loss on 0.84 Gbps, an ordinary internet link.
Conventional data-parallel across 8 datacenters needs roughly 198 Gbps of bandwidth between sites — the kind of dedicated fiber-optic link normally reserved for the largest cloud regions. Decoupled DiLoCo reaches the same training loss on 0.84 Gbps, an ordinary internet link.
The wider picture comes into focus once these two numbers are placed on a log-scale interconnect spectrum alongside the other common link types.
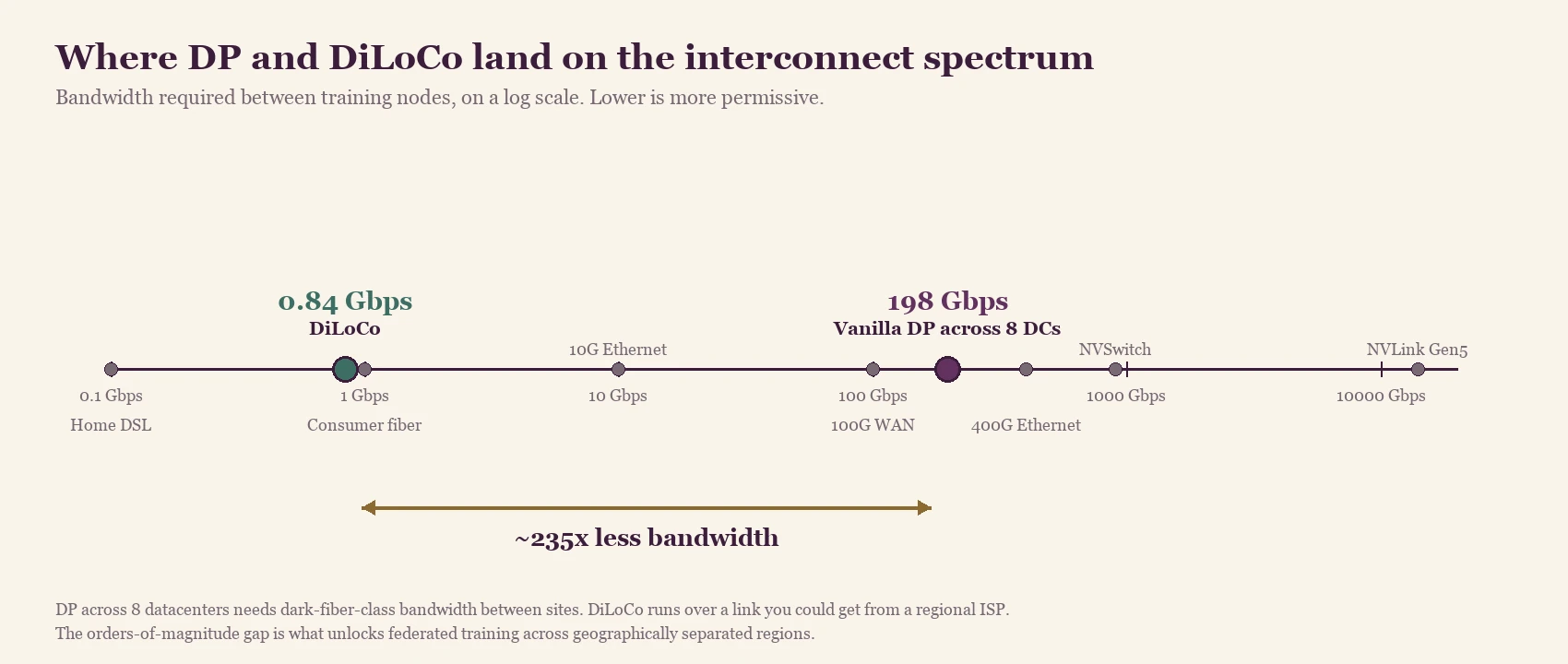 Where the two numbers sit on the broader interconnect spectrum. DP across 8 datacenters needs bandwidth in the same band as 100G WAN and 400G Ethernet. At 0.84 Gbps, DiLoCo's requirement actually falls just below consumer gigabit fiber — a link any regional ISP can provide. The orders-of-magnitude gap is why training across geographically separated regions works at all.
Where the two numbers sit on the broader interconnect spectrum. DP across 8 datacenters needs bandwidth in the same band as 100G WAN and 400G Ethernet. At 0.84 Gbps, DiLoCo's requirement actually falls just below consumer gigabit fiber — a link any regional ISP can provide. The orders-of-magnitude gap is why training across geographically separated regions works at all.
DeepMind backed the simulations with a real production run that trained a 12B-parameter Gemma 4 model across four separate U.S. regions on 2–5 Gbps of wide-area networking (WAN) [1]. The run completed roughly 20x faster than a conventional synchronous run would have managed at that scale. ML quality came in at 64.1% average accuracy across their eval suite versus 64.4% for a single-site baseline, which is a difference small enough to be statistical noise. This is not a paper proposal; it is a production system DeepMind already operated end-to-end.
You can mix chip generations in the same run
The result most coverage underplayed is that DeepMind reports successfully training with TPU v6e and TPU v5p in the same run, which combines two different chip generations running at different speeds with no ML performance penalty. The faster generation contributes more updates per unit time and the slower one contributes fewer updates per unit time, and the loss curves match a homogeneous baseline run on a single chip family.
This is a new result, and it changes the depreciation curve on AI infrastructure.
Every enterprise budget for AI hardware today assumes generation N becomes obsolete the moment generation N+1 ships, which is why depreciation schedules sit at 3 years for production AI hardware where they used to be 5 to 7 years for general compute. DiLoCo proposes a different default, in which generations are composed rather than replaced. An older accelerator generation can stay productive for substantially longer, contributing real capacity to a frontier-scale run alongside newer hardware in the same run.
For procurement teams, that reframes the lease-versus-buy question, the supply-chain hedging strategy, and the vendor lock-in conversation. It matters specifically for non-NVIDIA accelerators (IBM's Spyre roadmap, AWS Trainium, Huawei Ascend, Cerebras WSE), because mixed-hardware training means a different accelerator family can contribute capacity to a frontier-scale run without having to match NVIDIA's spec sheet point for point. The bar for being useful in a federated run drops substantially, while the bar for being the highest-performing chip in absolute terms remains as high as it ever was.
For those of us building accelerator stacks (on the IBM Research side, that is what my group does with torch-spyre and the Spyre AIU, which is IBM's Artificial Intelligence Unit accelerator), this is the result with the longest-lasting effect. Mixed-hardware federated training is the architectural assumption that lets a non-NVIDIA accelerator generation be useful from day one, rather than having to clear a frontier-leader bar before it is worth shipping at scale.
Why DeepMind is publishing this now
It is tempting to read DiLoCo as a cost-reduction story about cheaper bandwidth and more efficient training, but that framing is at least incomplete and probably wrong.
The reason DeepMind, the biggest practitioner of gigawatt-scale single-site training, is publishing federated training research is that power has become the binding constraint at the top of the field. A gigawatt-scale site needs its own dedicated substation, the grid in Northern Virginia is already maxed out, and new large interconnects are running into multi-year permitting delays. The economics of "build a single huge cluster" run into the physics of "you need a power line to it" before they run into anything else.
DiLoCo is also a hedge against power, permitting, and supply-chain bottlenecks. If a lab can train a frontier model across four medium-sized regional sites instead of one giant site, it can route around the grid constraint and the permitting process at the same time. That is not a marginal benefit, and for the next round of model scaling it might be the difference between training a frontier model at all and being unable to train one.
Training will federate while inference keeps concentrating
The natural reaction to DiLoCo is to assume that everything decentralizes from this point forward, but the two workloads do not behave the same way. Training and inference want opposite topologies, and the rest of the stack will reorganize itself around that asymmetry.
Training is throughput-bound and tolerant of latency. A training run can spend hours between synchronizations, can absorb a 50ms WAN round-trip into a multi-hour inner-step loop, and can keep making progress even if one island vanishes for ten minutes. Federation is therefore a natural fit for the training workload.
Inference is latency-bound in a way that training is not. A user typing into a chat window expects the first token in under a second, the KV cache needs to stay colocated with the compute that is reading from it, and cross-region calls add 30 to 80ms before any work even begins. Inference therefore wants colocated KV caches, tight intra-rack synchronization, and the lowest possible end-to-end latency, which makes federation hostile to the workload rather than helpful.
The stack splits as a result. Training will federate across regional sites while inference will keep concentrating in latency-optimized hyperscale regions, and each side will have different hardware optimizations and different procurement strategies attached to it. The phrase "AI data center" will come to refer to two physically distinct things that happen to share the same GPU SKUs underneath.
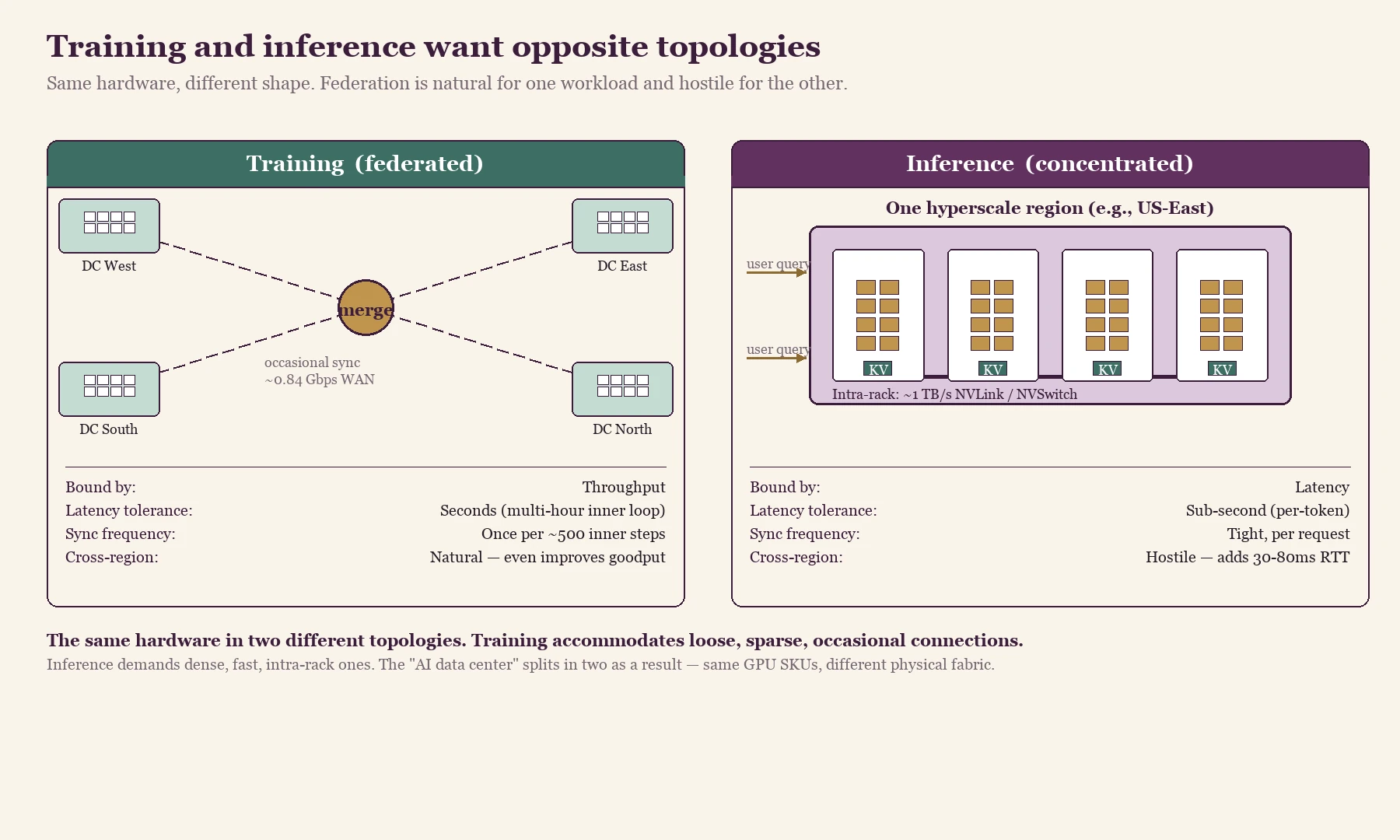 Left: training as a federation of regional DCs syncing occasionally through a central merge node over ~0.84 Gbps WAN. Right: inference as a single hyperscale region with dense intra-rack NVLink/NVSwitch fabric and KV caches co-located with compute. Same GPU SKUs in both pictures; the physical topology around them is what differs.
Left: training as a federation of regional DCs syncing occasionally through a central merge node over ~0.84 Gbps WAN. Right: inference as a single hyperscale region with dense intra-rack NVLink/NVSwitch fabric and KV caches co-located with compute. Same GPU SKUs in both pictures; the physical topology around them is what differs.
This has implications all the way down to silicon design. A chip optimized for training-time goodput under realistic failure rates (long mean time between failures, graceful degradation when components fail, asynchronous-friendly memory hierarchy) is a different chip than one optimized for inference-time tail latency (predictable kernel timing, KV-cache-friendly memory bandwidth, fast intra-rack networking). Vendors that try to ship one chip for both workloads will lose to vendors that specialize.
Stranded compute becomes useful capacity
One more implication is worth flagging, and I do not think procurement and infrastructure teams have caught up to it yet. A substantial amount of compute sits stranded today, and DiLoCo turns that stranded pool into usable capacity.
The stranded pool includes partial clusters that are not big enough for frontier training, off-peak time on production-serving fleets, geographically isolated facilities that cannot get enough bandwidth to participate in a tightly-coupled run, and older accelerator generations that no one wants to dedicate to a frontier run.
DiLoCo turns those stranded resources into useful capacity. Combined with the power constraint described above, this points to a future where training a frontier model looks more like running a globally distributed batch job than like booking a single site for 90 days, which implies a different financial model and a different industrial structure for the labs that operate at this scale.
The result also makes the research lineage worth pointing at directly. Decoupled DiLoCo combines four Google research lines, beginning with Federated Learning (Brendan McMahan and the FedAvg work going back to 2017) [4], continuing through Pathways (Barham, Isard, Dean, and the asynchronous-dataflow work from 2022) [5], then DiLoCo itself (Douillard's work from 2023) [2], and finally Streaming DiLoCo (Douillard et al., January 2025) [6], which introduced overlapping communication between inner-loop and outer-loop steps and is the immediate bridge between the original DiLoCo and the decoupled version. Arthur Douillard has been first author across the entire DiLoCo sequence, which makes this body of work a sustained research program rather than a single isolated paper.
What this changes for the next round of training
For labs choosing where to spend their next training dollar, DiLoCo does not make the megacluster obsolete; it makes the single-site assumption optional, and that distinction matters more than it might appear at first.
The teams that benefit most are the ones whose binding constraint is not compute but siting, which covers power, permitting, regional sovereignty, and supply-chain hedging all at once. For those teams, DiLoCo offers a path to the same scale on a different set of real estate. Teams that already operate a gigawatt single-site cluster do not need to reorganize around DiLoCo tomorrow, but the next generation of their stack should be designed for mixed-hardware federated runs with fault tolerance built in from the start. Otherwise they remain locked into the single-site assumption every time they build out.
The bandwidth story will keep getting most of the press coverage, but the mixed-hardware result and the goodput gap are the two findings that will change how training budgets are set inside the labs. The split between federated training and concentrated inference is the architectural pattern I would watch most closely over the next two years.
The model that emerges from one of these federated training runs will look, on the inference side, exactly like every other model that gets shipped. The infrastructure underneath and the question of who can afford to operate it will look very different.
References
[1] Google DeepMind, "Decoupled DiLoCo: Resilient, Distributed AI Training at Scale," DeepMind blog, April 2026.
[2] Douillard, A. et al., "DiLoCo: Distributed Low-Communication Training of Language Models," arXiv:2311.08105, November 2023.
[3] Google DeepMind, "Decoupled DiLoCo for Resilient Distributed Pre-training," arXiv:2604.21428, April 2026.
[4] McMahan, H. B. et al., "Communication-Efficient Learning of Deep Networks from Decentralized Data," AISTATS 2017 (FedAvg).
[5] Barham, P. et al., "Pathways: Asynchronous Distributed Dataflow for ML," MLSys 2022.
[6] Douillard, A. et al., "Streaming DiLoCo with overlapping communication: Towards a Distributed Free Lunch," arXiv:2501.18512, January 2025.
Discussion
Sign in with GitHub to leave a comment or react. Threads are public and live in this site's GitHub Discussions.